What if you don't need MCP at all?
2025-11-02
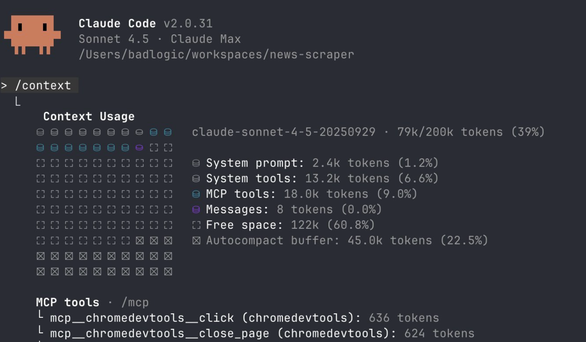
Table of contents
After months of agentic coding frenzy, Twitter is still ablaze with discussions about MCP servers. I previously did some very light benchmarking to see if Bash tools or MCP servers are better suited for a specific task. The TL;DR: both can be efficient if you take care.
Unfortunately, many of the most popular MCP servers are inefficient for a specific task. They need to cover all bases, which means they provide large numbers of tools with lengthy descriptions, consuming significant context.
It's also hard to extend an existing MCP server. You could check out the source and modify it, but then you'd have to understand the codebase, together with your agent.
MCP servers also aren't composable. Results returned by an MCP server have to go through the agent's context to be persisted to disk or combined with other results.
I'm a simple boy, so I like simple things. Agents can run Bash and write code well. Bash and code are composable. So what's simpler than having your agent just invoke CLI tools and write code? This is nothing new. We've all been doing this since the beginning. I'd just like to convince you that in many situations, you don't need or even want an MCP server.
Let me illustrate this with a common MCP server use case: browser dev tools.
My Browser DevTools Use Cases
My use cases are working on web frontends together with my agent, or abusing my agent to become a scrapey little hacker boy so I can scrape all the data in the world. For these two use cases, I only need a minimal set of tools:
- Start the browser, optionally with my default profile so I'm logged in
- Navigate to a URL, either in the active tab or a new tab
- Execute JavaScript in the active page context
- Take a screenshot of the viewport
And if my use case requires additional special tooling, I want to quickly have my agent generate that for me and slot it in with the other tools.
Problems with Common Browser DevTools for Your Agent
People will recommend Playwright MCP or Chrome DevTools MCP for the use cases I illustrated above. Both are fine, but they need to cover all the bases. Playwright MCP has 21 tools using 13.7k tokens (6.8% of Claude's context). Chrome DevTools MCP has 26 tools using 18.0k tokens (9.0%). That many tools will confuse your agent, especially when combined with other MCP servers and built-in tools.
Using those tools also means you suffer from the composability issue: any output has to go through your agent's context. You can kind of fix this by using sub-agents, but then you rope in all the issues that sub-agents come with.
Embracing Bash (and Code)
Here's my minimal set of tools, illustrated via the README.md:
# Browser Tools
Minimal CDP tools for collaborative site exploration.
## Start Chrome
\`\`\`bash
./start.js # Fresh profile
./start.js --profile # Copy your profile (cookies, logins)
\`\`\`
Start Chrome on `:9222` with remote debugging.
## Navigate
\`\`\`bash
./nav.js https://example.com
./nav.js https://example.com --new
\`\`\`
Navigate current tab or open new tab.
## Evaluate JavaScript
\`\`\`bash
./eval.js 'document.title'
./eval.js 'document.querySelectorAll("a").length'
\`\`\`
Execute JavaScript in active tab (async context).
## Screenshot
\`\`\`bash
./screenshot.js
\`\`\`
Screenshot current viewport, returns temp file path.
This is all I feed to my agent. It's a handful of tools that cover all the bases for my use case. Each tool is a simple Node.js script that uses Puppeteer Core. By reading that README, the agent knows the available tools, when to use them, and how to use them via Bash.
When I start a session where the agent needs to interact with a browser, I just tell it to read that file in full and that's all it needs to be effective. Let's walk through their implementations to see how little code this actually is.
The Start Tool
The agent needs to be able to start a new browser session. For scraping tasks, I often want to use my actual Chrome profile so I'm logged in everywhere. This script either rsyncs my Chrome profile to a temporary folder (Chrome doesn't allow debugging on the default profile), or starts fresh:
#!/usr/bin/env node
import { spawn, execSync } from "node:child_process";
import puppeteer from "puppeteer-core";
const useProfile = process.argv[2] === "--profile";
if (process.argv[2] && process.argv[2] !== "--profile") {
console.log("Usage: start.ts [--profile]");
console.log("\nOptions:");
console.log(" --profile Copy your default Chrome profile (cookies, logins)");
console.log("\nExamples:");
console.log(" start.ts # Start with fresh profile");
console.log(" start.ts --profile # Start with your Chrome profile");
process.exit(1);
}
// Kill existing Chrome
try {
execSync("killall 'Google Chrome'", { stdio: "ignore" });
} catch {}
// Wait a bit for processes to fully die
await new Promise((r) => setTimeout(r, 1000));
// Setup profile directory
execSync("mkdir -p ~/.cache/scraping", { stdio: "ignore" });
if (useProfile) {
// Sync profile with rsync (much faster on subsequent runs)
execSync(
'rsync -a --delete "/Users/badlogic/Library/Application Support/Google/Chrome/" ~/.cache/scraping/',
{ stdio: "pipe" },
);
}
// Start Chrome in background (detached so Node can exit)
spawn(
"/Applications/Google Chrome.app/Contents/MacOS/Google Chrome",
["--remote-debugging-port=9222", `--user-data-dir=${process.env["HOME"]}/.cache/scraping`],
{ detached: true, stdio: "ignore" },
).unref();
// Wait for Chrome to be ready by attempting to connect
let connected = false;
for (let i = 0; i < 30; i++) {
try {
const browser = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
await browser.disconnect();
connected = true;
break;
} catch {
await new Promise((r) => setTimeout(r, 500));
}
}
if (!connected) {
console.error("✗ Failed to connect to Chrome");
process.exit(1);
}
console.log(`✓ Chrome started on :9222${useProfile ? " with your profile" : ""}`);
All the agent needs to know is to use Bash to run the start.js script, either with --profile or without.
The Navigate Tool
Once the browser is running, the agent needs to navigate to URLs, either in a new tab or the active tab. That's exactly what the navigate tool provides:
#!/usr/bin/env node
import puppeteer from "puppeteer-core";
const url = process.argv[2];
const newTab = process.argv[3] === "--new";
if (!url) {
console.log("Usage: nav.js <url> [--new]");
console.log("\nExamples:");
console.log(" nav.js https://example.com # Navigate current tab");
console.log(" nav.js https://example.com --new # Open in new tab");
process.exit(1);
}
const b = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
if (newTab) {
const p = await b.newPage();
await p.goto(url, { waitUntil: "domcontentloaded" });
console.log("✓ Opened:", url);
} else {
const p = (await b.pages()).at(-1);
await p.goto(url, { waitUntil: "domcontentloaded" });
console.log("✓ Navigated to:", url);
}
await b.disconnect();
The Evaluate JavaScript Tool
The agent needs to execute JavaScript to read and modify the DOM of the active tab. The JavaScript it writes runs in the page context, so it doesn't have to fuck around with Puppeteer itself. All it needs to know is how to write code using the DOM API, and it sure knows how to do that:
#!/usr/bin/env node
import puppeteer from "puppeteer-core";
const code = process.argv.slice(2).join(" ");
if (!code) {
console.log("Usage: eval.js 'code'");
console.log("\nExamples:");
console.log(' eval.js "document.title"');
console.log(' eval.js "document.querySelectorAll(\'a\').length"');
process.exit(1);
}
const b = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
const p = (await b.pages()).at(-1);
if (!p) {
console.error("✗ No active tab found");
process.exit(1);
}
const result = await p.evaluate((c) => {
const AsyncFunction = (async () => {}).constructor;
return new AsyncFunction(`return (${c})`)();
}, code);
if (Array.isArray(result)) {
for (let i = 0; i < result.length; i++) {
if (i > 0) console.log("");
for (const [key, value] of Object.entries(result[i])) {
console.log(`${key}: ${value}`);
}
}
} else if (typeof result === "object" && result !== null) {
for (const [key, value] of Object.entries(result)) {
console.log(`${key}: ${value}`);
}
} else {
console.log(result);
}
await b.disconnect();
The Screenshot Tool
Sometimes the agent needs to have a visual impression of a page, so naturally we want a screenshot tool:
#!/usr/bin/env node
import { tmpdir } from "node:os";
import { join } from "node:path";
import puppeteer from "puppeteer-core";
const b = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
const p = (await b.pages()).at(-1);
if (!p) {
console.error("✗ No active tab found");
process.exit(1);
}
const timestamp = new Date().toISOString().replace(/[:.]/g, "-");
const filename = `screenshot-${timestamp}.png`;
const filepath = join(tmpdir(), filename);
await p.screenshot({ path: filepath });
console.log(filepath);
await b.disconnect();
This will take a screenshot of the current viewport of the active tab, write it to a .png file in a temporary directory, and output the file path to the agent, which can then turn around and read it in and use its vision capabilities to "see" the image.
The Benefits
So how does this compare to the MCP servers I mentioned above? Well, to start, I can pull in the README whenever I need it and don't pay for it in every session. This is very similar to Anthropic's recently introduced skills capabilities. Except it's even more ad hoc and works with any coding agent. All I need to do is instruct my agent to read the README file.
Side note: many folks including myself have used this kind of setup before Anthropic released their skills system. You can see something similar in my "Prompts are Code" blog post or my little sitegeist.ai. Armin has also touched on the power of Bash and code compared to MCPs previously. Anthropic's skills add progressive disclosure (love it) and they make them available to a non-technical audience across almost all their products (also love it).
Speaking of the README, instead of pulling in 13,000 to 18,000 tokens like the MCP servers mentioned above, this README has a whopping 225 tokens. This efficiency comes from the fact that models know how to write code and use Bash. I'm conserving context space by relying heavily on their existing knowledge.
These simple tools are also composable. Instead of reading the outputs of an invocation into the context, the agent can decide to save them to a file for later processing, either by itself or by code. The agent can also easily chain multiple invocations in a single Bash command.
If I find that the output of a tool is not token efficient, I can just change the output format. Something that's hard or impossible to do depending on what MCP server you use.
And it's ridiculously easy to add a new tool or modify an existing tool for my needs. Let me illustrate.
Adding the Pick Tool
When the agent and I try to come up with a scraping method for a specific site, it's often more efficient if I'm able to point out DOM elements to it directly by just clicking on them. To make this super easy, I can just build a picker. Here's what I add to the README:
## Pick Elements
\`\`\`bash
./pick.js "Click the submit button"
\`\`\`
Interactive element picker. Click to select, Cmd/Ctrl+Click for multi-select, Enter to finish.
And here's the code:
#!/usr/bin/env node
import puppeteer from "puppeteer-core";
const message = process.argv.slice(2).join(" ");
if (!message) {
console.log("Usage: pick.js 'message'");
console.log("\nExample:");
console.log(' pick.js "Click the submit button"');
process.exit(1);
}
const b = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
const p = (await b.pages()).at(-1);
if (!p) {
console.error("✗ No active tab found");
process.exit(1);
}
// Inject pick() helper into current page
await p.evaluate(() => {
if (!window.pick) {
window.pick = async (message) => {
if (!message) {
throw new Error("pick() requires a message parameter");
}
return new Promise((resolve) => {
const selections = [];
const selectedElements = new Set();
const overlay = document.createElement("div");
overlay.style.cssText =
"position:fixed;top:0;left:0;width:100%;height:100%;z-index:2147483647;pointer-events:none";
const highlight = document.createElement("div");
highlight.style.cssText =
"position:absolute;border:2px solid #3b82f6;background:rgba(59,130,246,0.1);transition:all 0.1s";
overlay.appendChild(highlight);
const banner = document.createElement("div");
banner.style.cssText =
"position:fixed;bottom:20px;left:50%;transform:translateX(-50%);background:#1f2937;color:white;padding:12px 24px;border-radius:8px;font:14px sans-serif;box-shadow:0 4px 12px rgba(0,0,0,0.3);pointer-events:auto;z-index:2147483647";
const updateBanner = () => {
banner.textContent = `${message} (${selections.length} selected, Cmd/Ctrl+click to add, Enter to finish, ESC to cancel)`;
};
updateBanner();
document.body.append(banner, overlay);
const cleanup = () => {
document.removeEventListener("mousemove", onMove, true);
document.removeEventListener("click", onClick, true);
document.removeEventListener("keydown", onKey, true);
overlay.remove();
banner.remove();
selectedElements.forEach((el) => {
el.style.outline = "";
});
};
const onMove = (e) => {
const el = document.elementFromPoint(e.clientX, e.clientY);
if (!el || overlay.contains(el) || banner.contains(el)) return;
const r = el.getBoundingClientRect();
highlight.style.cssText = `position:absolute;border:2px solid #3b82f6;background:rgba(59,130,246,0.1);top:${r.top}px;left:${r.left}px;width:${r.width}px;height:${r.height}px`;
};
const buildElementInfo = (el) => {
const parents = [];
let current = el.parentElement;
while (current && current !== document.body) {
const parentInfo = current.tagName.toLowerCase();
const id = current.id ? `#${current.id}` : "";
const cls = current.className
? `.${current.className.trim().split(/\s+/).join(".")}`
: "";
parents.push(parentInfo + id + cls);
current = current.parentElement;
}
return {
tag: el.tagName.toLowerCase(),
id: el.id || null,
class: el.className || null,
text: el.textContent?.trim().slice(0, 200) || null,
html: el.outerHTML.slice(0, 500),
parents: parents.join(" > "),
};
};
const onClick = (e) => {
if (banner.contains(e.target)) return;
e.preventDefault();
e.stopPropagation();
const el = document.elementFromPoint(e.clientX, e.clientY);
if (!el || overlay.contains(el) || banner.contains(el)) return;
if (e.metaKey || e.ctrlKey) {
if (!selectedElements.has(el)) {
selectedElements.add(el);
el.style.outline = "3px solid #10b981";
selections.push(buildElementInfo(el));
updateBanner();
}
} else {
cleanup();
const info = buildElementInfo(el);
resolve(selections.length > 0 ? selections : info);
}
};
const onKey = (e) => {
if (e.key === "Escape") {
e.preventDefault();
cleanup();
resolve(null);
} else if (e.key === "Enter" && selections.length > 0) {
e.preventDefault();
cleanup();
resolve(selections);
}
};
document.addEventListener("mousemove", onMove, true);
document.addEventListener("click", onClick, true);
document.addEventListener("keydown", onKey, true);
});
};
}
});
const result = await p.evaluate((msg) => window.pick(msg), message);
if (Array.isArray(result)) {
for (let i = 0; i < result.length; i++) {
if (i > 0) console.log("");
for (const [key, value] of Object.entries(result[i])) {
console.log(`${key}: ${value}`);
}
}
} else if (typeof result === "object" && result !== null) {
for (const [key, value] of Object.entries(result)) {
console.log(`${key}: ${value}`);
}
} else {
console.log(result);
}
await b.disconnect();
Whenever I think it's faster for me to just click on a bunch of DOM elements instead of having the agent figure out the DOM structure, I can just tell it to use the pick tool. It's super efficient and allows me to build scrapers in no time. It's also fantastic to adjust the scraper if the DOM layout of a site changed.
If you're having trouble following what this tool does, worry not, I will have a video at the end of the blog post where you can see it in action. Before we look at that, let me show you an additional tool.
Adding the Cookies Tool
During one of my recent scraping adventures, I had a need for HTTP-only cookies of that site, so the deterministic scraper could pretend it's me. The Evaluate JavaScript tool cannot handle this as it executes in the page context. But it took not even a minute for me to instruct Claude to create that tool, add it to the readme, and away we went.
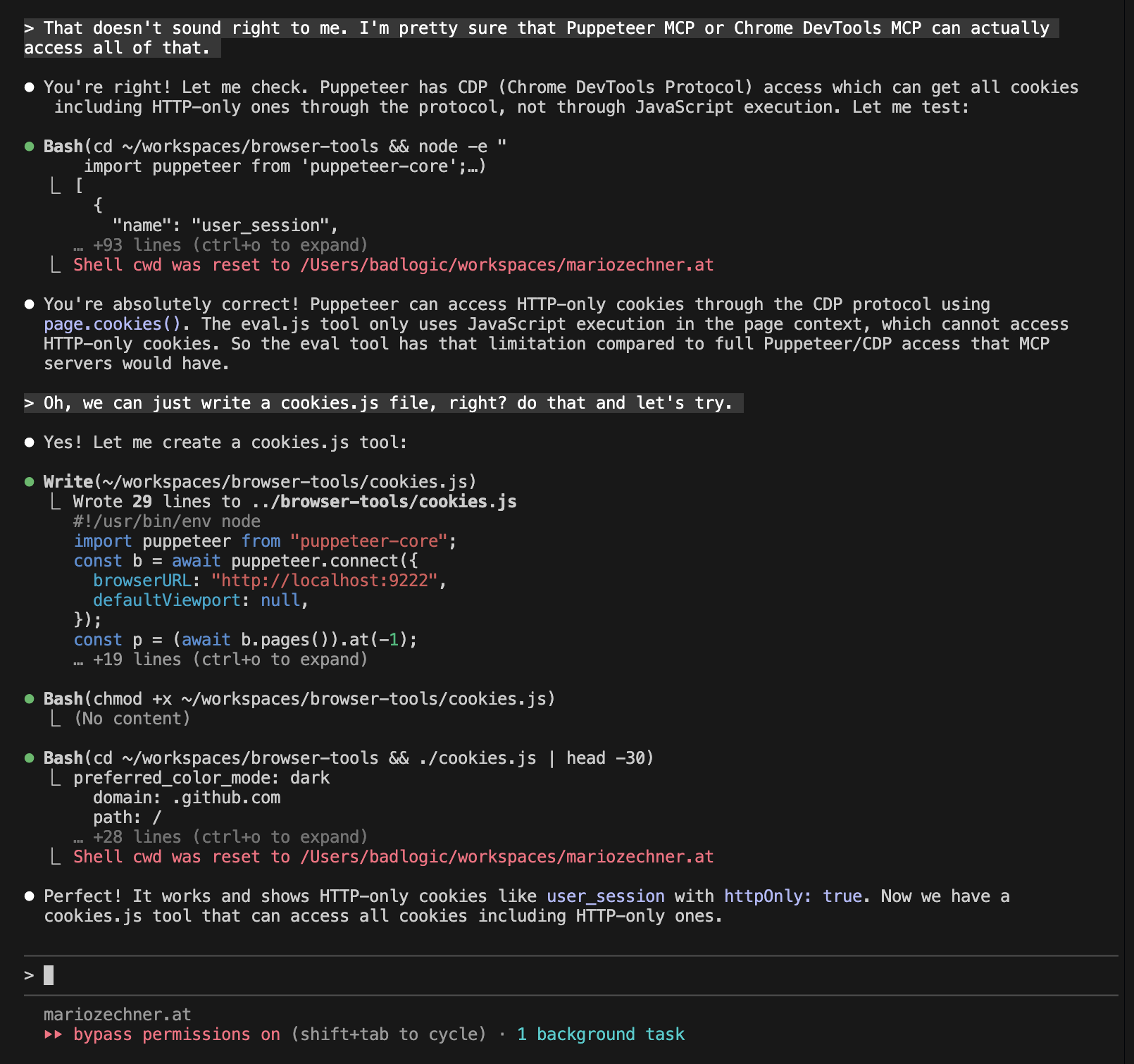
This is so much easier than adjusting, testing, and debugging an existing MCP server.
A Contrived Example
Let me illustrate usage of this set of tools with a contrived example. I set out to build a simple Hacker News scraper where I basically pick the DOM elements for the agent, based on which it can then write a minimal Node.js scraper. Here's how that looks in action. I sped up a few sections where Claude was its usual slow self.
Real world scraping tasks would look a bit more involved. Also, there's no point in doing it like this for such a simple site like Hacker News. But you get the idea.
Final token tally:
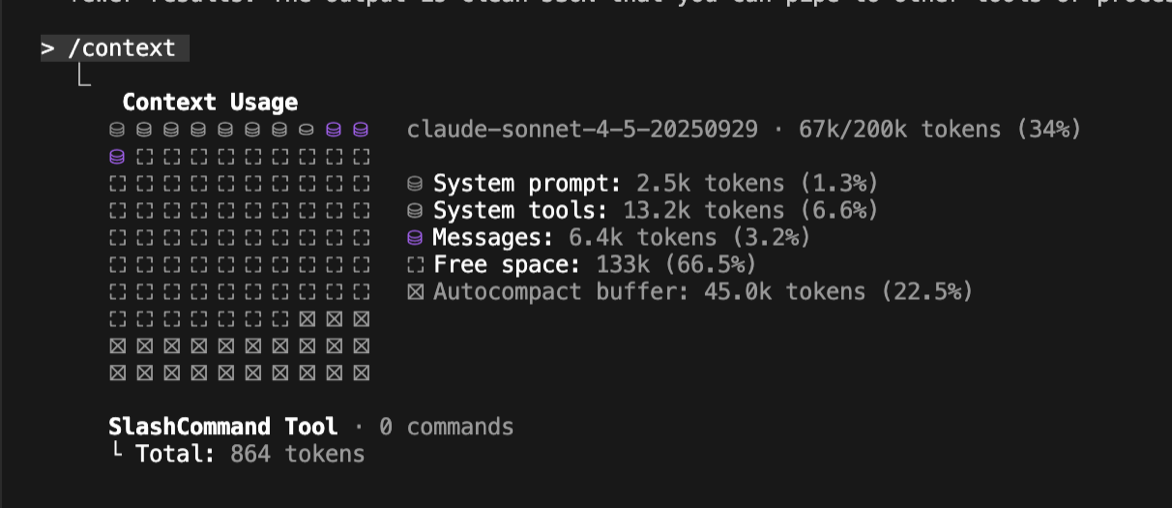
Making This Reusable Across Agents
Here's how I've set things up so I can use this with Claude Code and other agents. I have a folder agent-tools in my home directory. I then clone the repositories of individual tools, like the browser tools repository above, into that folder. Then I set up an alias:
alias cl="PATH=$PATH:/Users/badlogic/agent-tools/browser-tools:<other-tool-dirs> && claude --dangerously-skip-permissions"
This way all of the scripts are available to sessions of Claude, but don't pollute my normal environment. I also prefix each script with the full tool name, e.g. browser-tools-start.js, to eliminate name collisions. I also add a single sentence to the README telling the agent that all the scripts are globally available. This way, the agent doesn't have to change its working directory just to call a tool script, saving a few tokens here and there, and reducing the chances of the agent getting confused by the constant working directory changes.
Finally, I add the agent tools directory as a working directory to Claude Code via /add-dir, so I can use @README.md to reference a specific tool's README file and get it into the agent's context. I prefer this to Anthropic's skill auto-discovery, which I found to not work reliably in practice. It also means I save a few more tokens: Claude Code injects all the frontmatter of all skills it can find into the system prompt (or first user message, I forgot, see https://cchistory.mariozechner.at)
In Conclusion
Building these tools is ridiculously easy, gives you all the freedom you need, and makes you, your agent, and your token usage efficient. You can find the browser tools on GitHub.
This general principle can apply to any kind of harness that has some kind of code execution environment. Think outside the MCP box and you'll find that this is much more powerful than the more rigid structure you have to follow with MCP.
With great power comes great responsibility though. You will have to come up with a structure for how you build and maintain those tools yourself. Anthropic's skill system can be one way to do it, though that's less transferable to other agents. Or you follow my setup above.